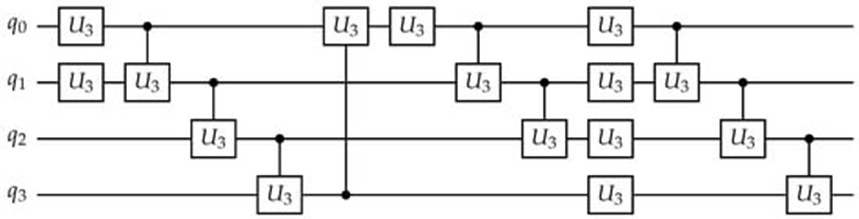
Training-Free Quantum Architecture Search under Realistic Noise via Expressibility-Guided Evolution
Designing noise-robust parameterized quantum circuits (PQCs) is a central challenge in the noisy intermediate-scale quantum (NISQ) regime. Existing quantum architecture search methods rely on training large SuperCircuits and evaluating SubCircuits under noisy execution, resulting in high computational cost and architecture assessments that depend on task-specific optimization and device noise. In this work, we propose a training-free quantum architecture search framework based on information-theoretic expressibility measures rather than performance-based estimators. We empirically show that noise-free KL-divergence-based expressibility exhibits a consistent monotonic association with noisy task loss across diverse circuit architectures and realistic hardware noise models. Leveraging this relationship, we introduce an expressibility-guided evolutionary search that requires neither SuperCircuit training nor noisy execution during the search phase. Since expressibility is evaluated independently of hardware noise, the method is inherently device-agnostic, enabling architectures to be reused across multiple quantum devices without re-running the search. Experiments using IBM-derived Qiskit noise models demonstrate that the proposed approach achieves competitive performance compared to SuperCircuit-based baselines, while substantially reducing computational cost. These results establish expressibility as an effective information-theoretic surrogate for ranking PQC architectures under realistic~noise.
Paper link: https://www.mdpi.com/1099-4300/28/3/330
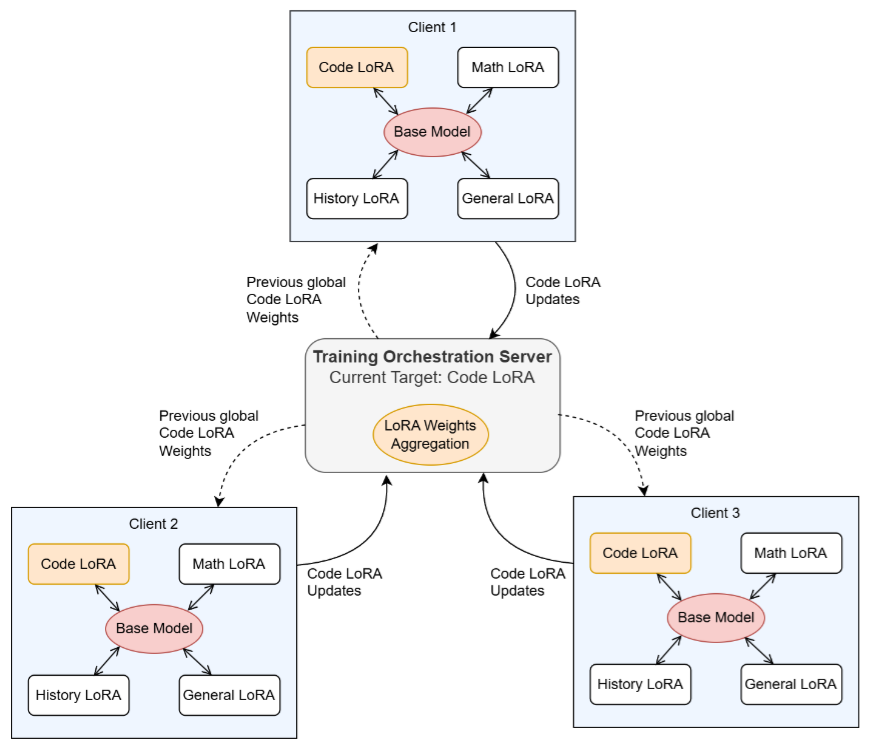
FedLoRASwitch: Efficient Federated Learning via LoRA Expert Hotswapping and Routing
FedLoRASwitch is a framework that combines federated learning (FL), Low-Rank Adaptation (LoRA), and Mixture-of-Experts (MoE) principles to enable the efficient and private adaptation of large language models (LLMs). The tool operates by collaboratively training multiple domain-specific LoRA “experts” (such as for math or coding) across decentralized clients without sharing raw data. At inference time, a lightweight Transformer router analyzes incoming queries to select the most relevant expert, which is then dynamically “hot-swapped” or merged with a frozen base model to generate a response. Experimental results show that this approach can provide substantial performance gains, such as an 8-fold increase in mathematical reasoning accuracy, while reducing communication overhead by approximately 40x compared to traditional full-parameter training.
Paper: https://www.es.mdu.se/pdf_publications/7245.pdf
Code: Will be shared later…
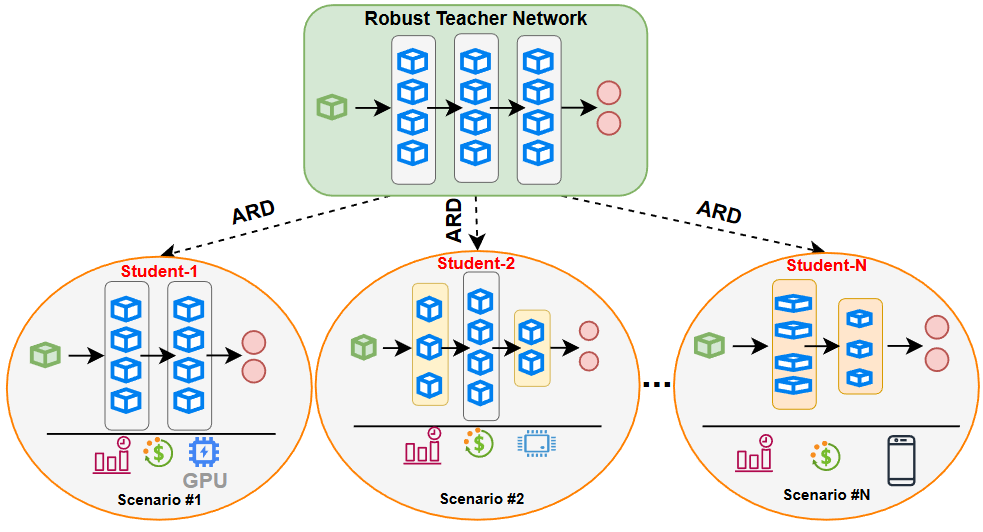
ProARD: Progressive Adversarial Robustness Distillation: Provide Wide Range of Robust Students
The Progressive Adversarial Robustness Distillation (ProARD) approach efficiently trains a wide range of robust student networks within a single dynamic network by using a three-step progressive sampling strategy. This strategy progressively reduces the size of the sampled student networks over the course of the training. In the first step, the depth and expansion are fixed, and different student networks are extracted by varying only the width (or kernel size for MobileNet). In the second step, the expansion is fixed while both the width (or kernel size) and depth are varied to train the student networks. Finally, the third step extracts and trains student networks by varying all three configuration parameters: width (or kernel size), depth, and expansion. In each step, robustness distillation is applied between the dynamic teacher and the selected students, and the student parameters are shared with the dynamic teacher network.
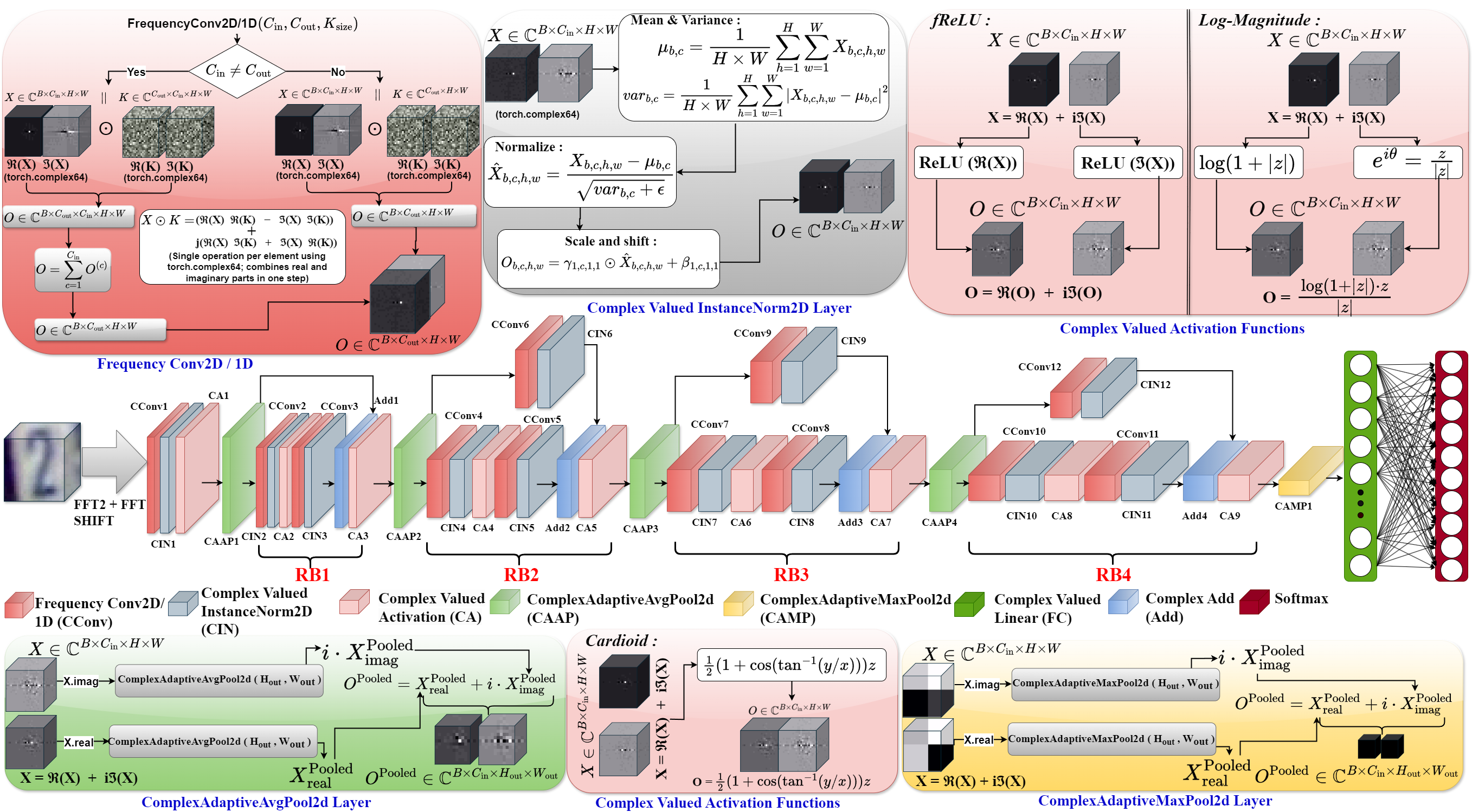
Frequency Domain Complex-Valued Convolutional Neural Network
This paper presents a fully complex-valued residual CNN that operates entirely in the frequency domain to efficiently process complex data. Traditional real-valued CNNs lose important phase information and are computationally intensive, while prior complex-valued models depend heavily on FFT/IFFT transformations and incomplete complex formulations. To address these issues, the authors design lightweight, fully complex building blocks—including complex convolution, normalization, pooling, and a new Log-Magnitude activation function that preserves phase and stabilizes gradient flow. This model significantly reduces computational complexity while maintaining expressive power. Evaluated across multiple datasets (MNIST, SVHN, MIT-BIH Arrhythmia, PTB Diagnostic ECG, DIAT-μRadHAR, and DIAT-μSAT), the proposed approach outperforms both real-valued and existing hybrid complex-valued CNNs in accuracy, efficiency, and generalization, demonstrating the potential of frequency-domain complex-valued deep learning for diverse real-world applications.
Paper: https://www.sciencedirect.com/science/article/pii/S0957417425025102
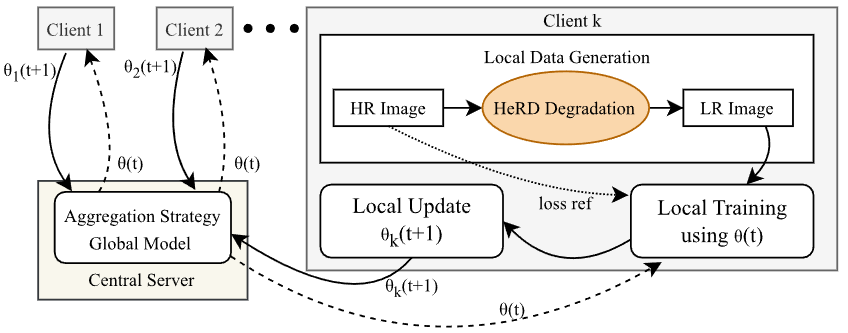
HeRD: Modelling Heterogeneous Degradations for Federated Super-Resolution in Satellite Imagery
This work, “HeRD: Modeling Heterogeneous Degradations for Federated Super-Resolution in Satellite Imagery,” introduces a novel strategy for training super-resolution models on decentralized satellite data while preserving privacy. Traditional methods often fail to account for the unique and complex image degradations caused by different satellite hardware, creating a gap between training and real-world application. The HeRD (Heterogeneous Realistic Degradation) strategy addresses this by realistically simulating these diverse, client-specific degradations—such as anisotropic blur and sensor noise—directly on each local device. This allows for the collaborative training of a powerful, global super-resolution model using federated learning, where raw data never leaves the owner’s control. Our extensive experiments show that this approach is highly effective, achieving image quality that is nearly on par with models trained on a centralized dataset, even in highly heterogeneous environments. This makes HeRD a viable, high-performance, and privacy-first solution for enhancing satellite imagery where data sovereignty is critical.
Paper: https://ieeexplore.ieee.org/abstract/document/11083581
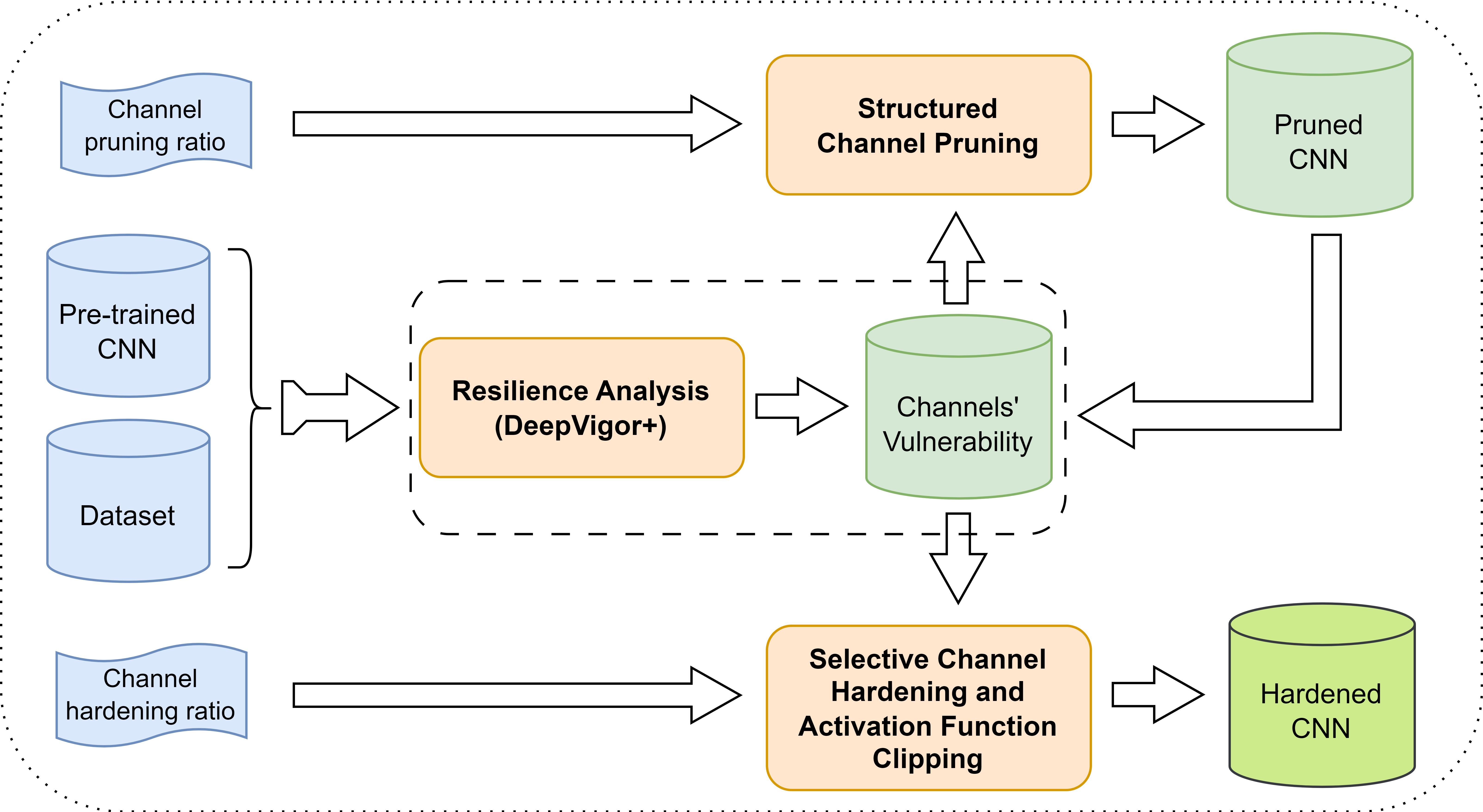
SentinelNN: A Framework for Fault Resilience Assessment and Enhancement of CNNs
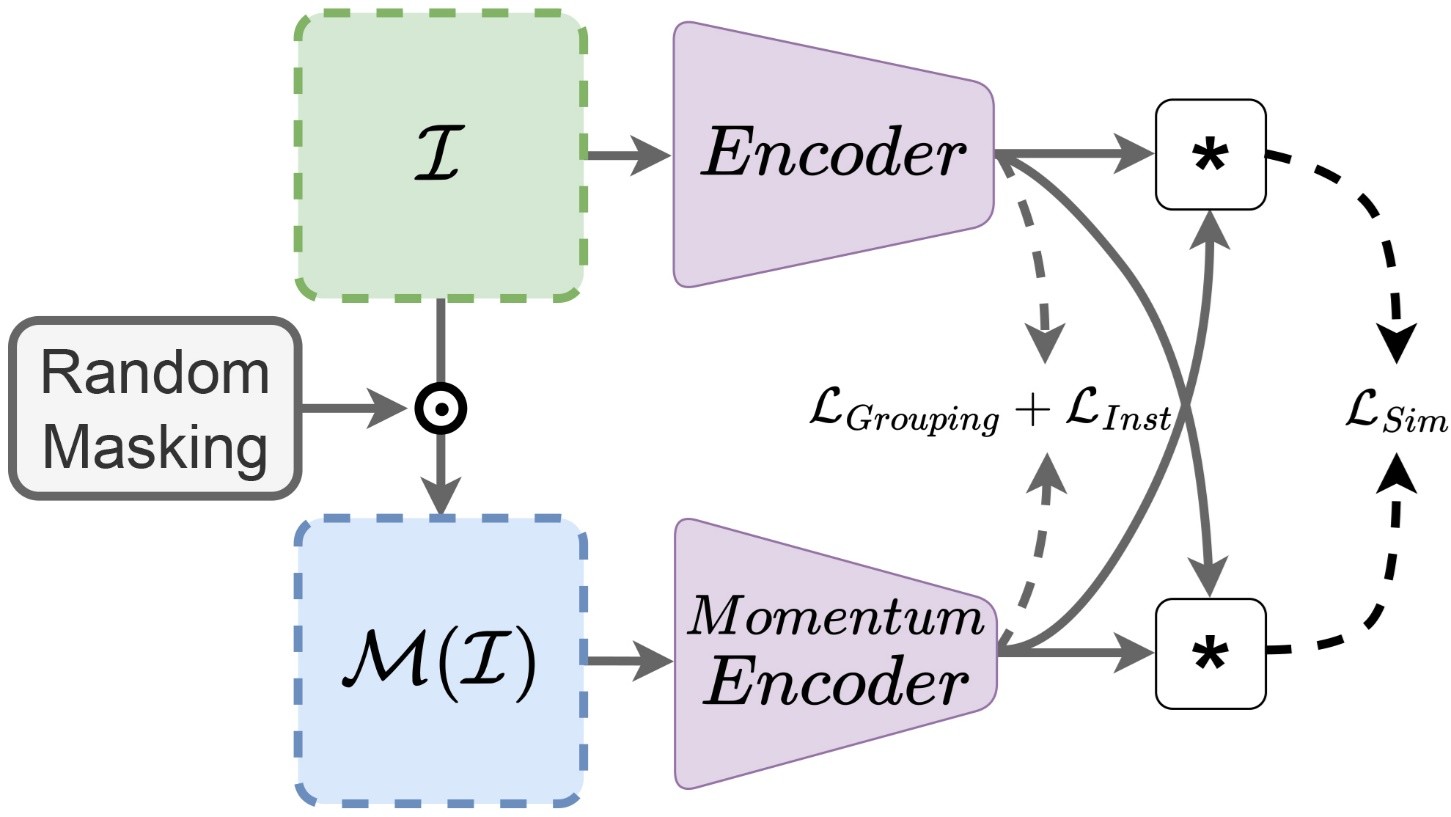
Contrastive Learning for Lane Detection via cross-similarity
Contrastive Learning for Lane Detection via cross-similarity (CLLD), is a self-supervised learning method that tackles this challenge by enhancing lane detection models’ resilience to real-world conditions that cause lane low visibility. CLLD is a novel multitask contrastive learning that trains lane detection approaches to detect lane markings even in low visible situations by integrating local feature contrastive learning (CL) with our new proposed operation cross-similarity. To ease of understanding some details are listed in the following:
- CLLD employs similarity learning to improve the performance of deep neural networks in lane detection, particularly in challenging scenarios.
- The approach aims to enhance the knowledge base of neural networks used in lane detection.
- Our experiments were carried out using ImageNet as a pretraining dataset. We employed pioneering lane detection models like RESA, CLRNet, and UNet, to evaluate the impact of our approach on model performances.
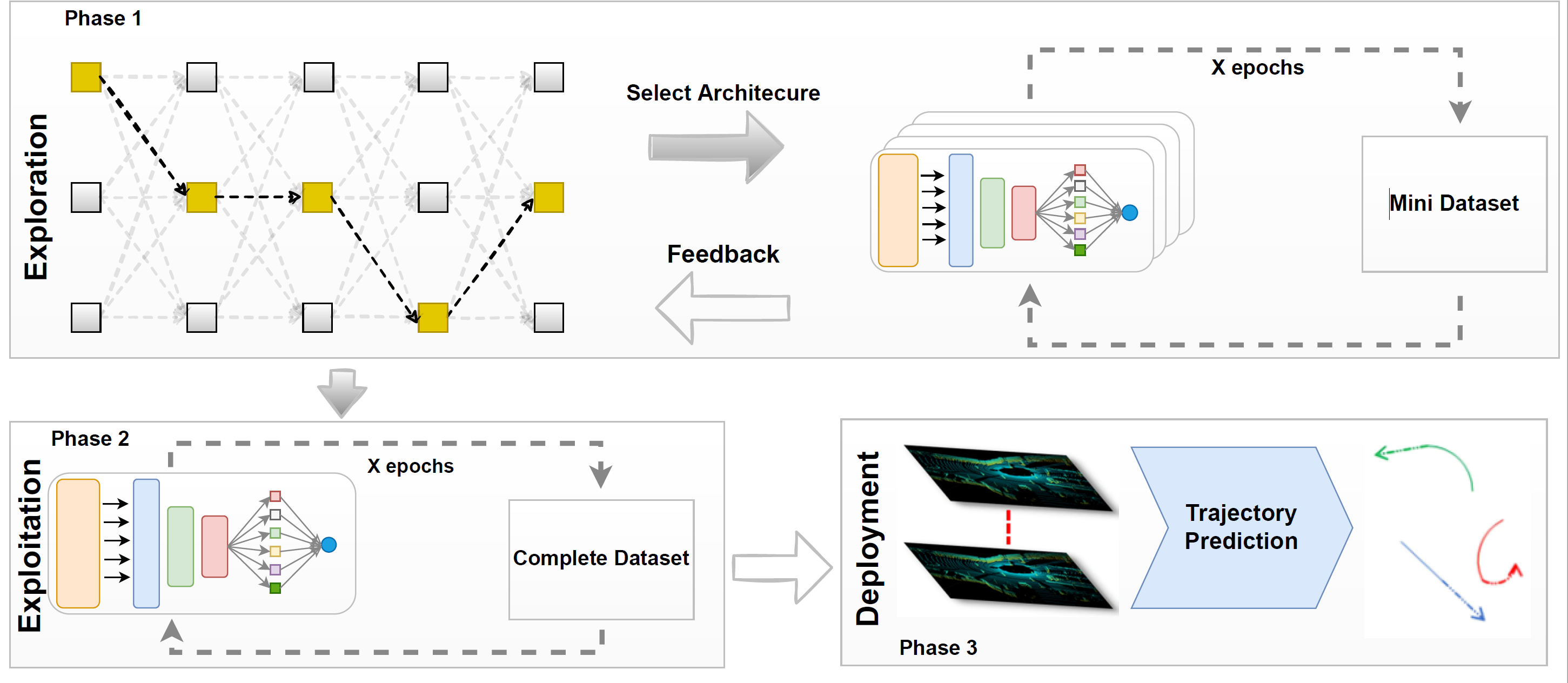
TrajectoryNAS: A Neural Architecture Search for Trajectory Prediction
This paper, TrajectoryNAS, uses Neural Architecture Search (NAS) to improve future trajectory prediction for autonomous systems, especially in autonomous driving (AD). Accurate predictions are vital for safety and efficiency. The study highlights how enhanced trajectory forecasting can improve Simultaneous Localization and Mapping (SLAM). It explores using 2D and 3D data, noting cameras’ strengths in classification, radar’s robust distance/velocity measurements, and LIDAR’s superior accuracy. The paper also examines various 3D data representations to optimize predictions.
In essence, TrajectoryNAS automates the design of predictive models to boost accuracy and efficiency, aiming for safer autonomous driving.
RReLU: Reliable ReLU Toolbox (RReLU) To Enhance Resilience of DNNs
The Reliable ReLU Toolbox (RReLU) is a powerful reliability tool designed to enhance the resiliency of deep neural networks (DNNs) by generating reliable ReLU activation functions. It is Implemented for the popular PyTorch deep learning platform. RReLU allows users to find a clipped ReLU activation function using various methods. This tool is highly versatile for dependability and reliability research, with applications ranging from resiliency analysis of classification networks to training resilient models and improving DNN interpretability.
RReLU includes all state-of-the-art activation restriction methods. These methods offer several advantages: they do not require retraining the entire model, avoid the complexity of fault-aware training, and are non-intrusive, meaning they do not necessitate any changes to an accelerator. RReLU serves as the research code accompanying the paper (ProAct: Progressive Training for Hybrid Clipped Activation Function to Enhance Resilience of DNNs), and it includes implementations of the following algorithms:
- ProAct (the proposed algorithm) (paper and (code).
- FitAct (paper and code).
- FtClipAct (paper and code).
- Ranger (paper and code).
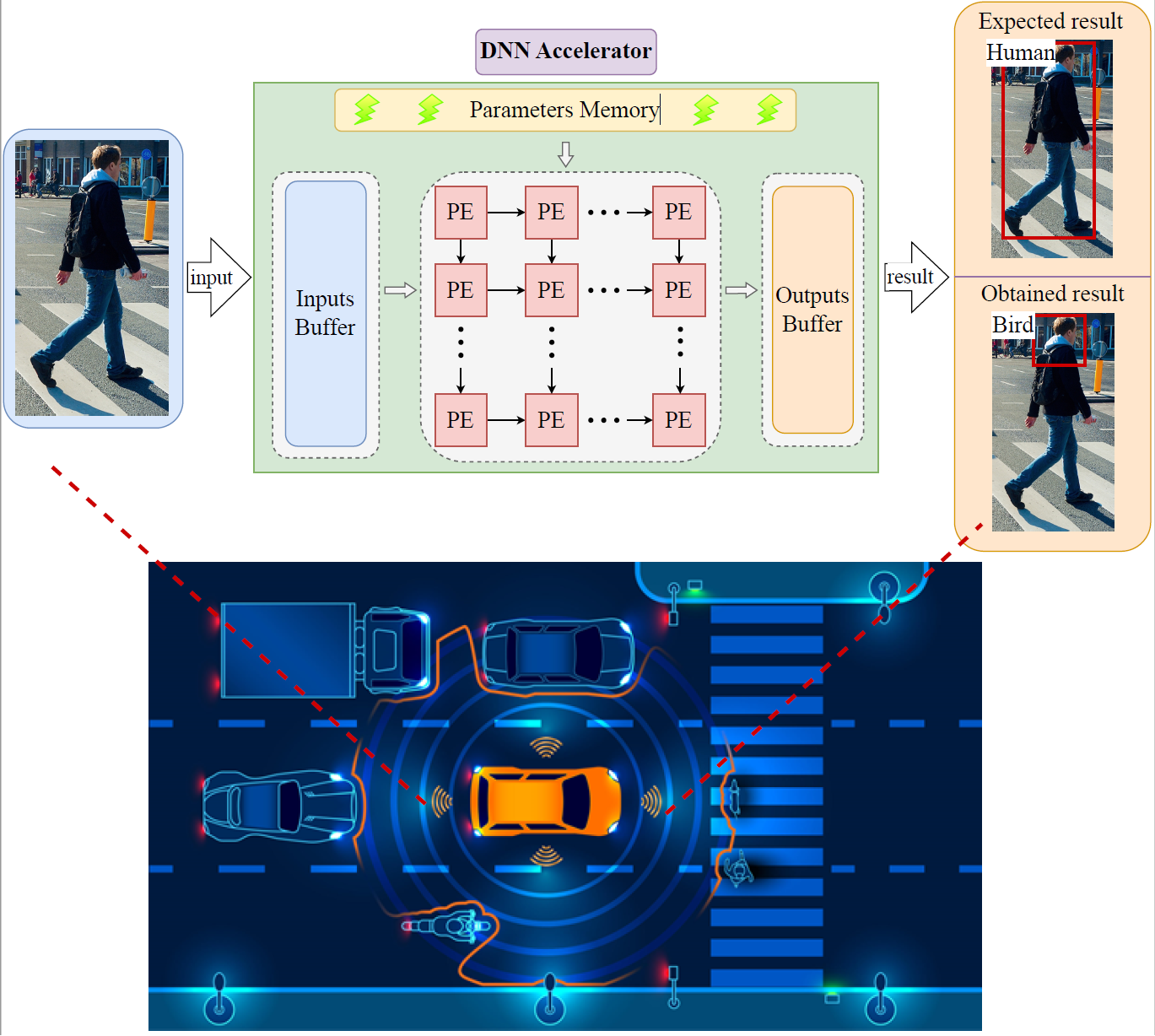
DASS: DIFFERENTIABLE ARCHITECTURE SEARCH FOR SPARSE NEURAL NETWORKS
The deployment of Deep Neural Networks (DNNs) on edge devices is hindered by the substantial gap between performance requirements and available processing power. While recent research has made significant strides in developing pruning methods to build a sparse network for reducing the computing overhead of DNNs, there remains considerable accuracy loss, especially at high pruning ratios. We find that the architectures designed for dense networks by differentiable architecture search methods are ineffective when pruning mechanisms are applied to them. The main reason is
that the current method does not support sparse architectures in their search space and uses a search objective that is made for dense networks and does not pay any attention to sparsity.
In this paper, we propose a new method to search for sparsity-friendly neural architectures. We do this by adding two new sparse operations to the search space and modifying the search objective. We propose two novel parametric SparseConv and SparseLinear operations in order to expand the search space to include sparse operations. In particular, these operations make a flexible search space due to using sparse parametric versions of linear and convolution operations. The proposed search objective lets us train the architecture based on the sparsity of the search space operations. Quantitative analyses demonstrate that our search architectures outperform those used in the stateof-the-art sparse networks on the CIFAR-10 and ImageNet datasets. In terms of performance and hardware effectiveness, DASS increases the accuracy of the sparse version of MobileNet-v2 from 73.44% to 81.35% (+7.91% improvement) with 3.87× faster inference time
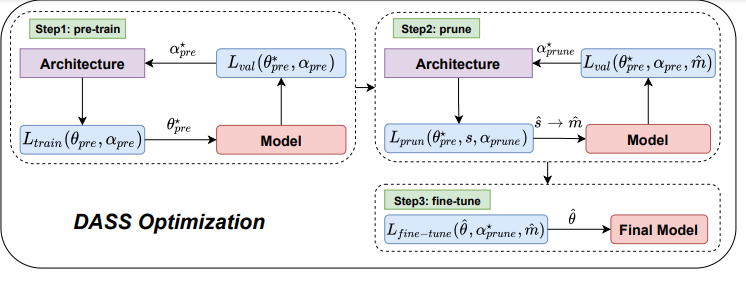
3DLaneNAS: Neural Architecture Search for Accurate and Light-Weight 3D Lane Detection
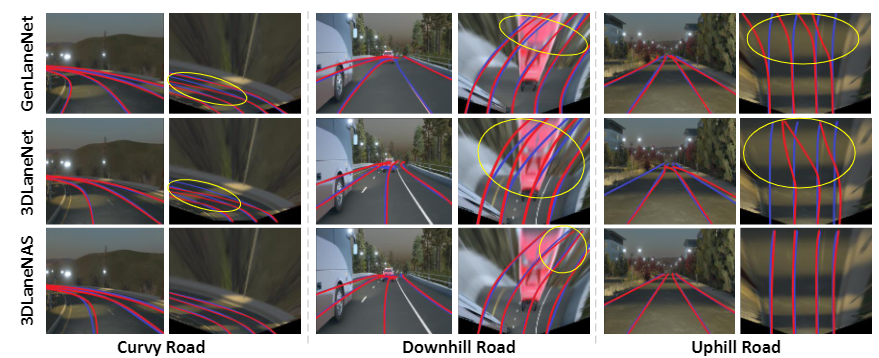
Lane detection is one of the most fundamental tasks for autonomous driving. It plays a crucial role in the lateral control and the precise localization of autonomous vehicles. Monocular 3D lane detection methods provide state-of-the-art results for estimating the position of lanes in 3D world coordinates using only the information obtained from the front-view camera. Recent advances in Neural Architecture Search (NAS) facilitate automated optimization of various computer vision tasks. NAS can automatically optimize monocular 3D lane detection methods to enhance the extraction and combination of visual features, consequently reducing computation loads and increasing accuracy. This paper proposes 3DLaneNAS, a multi-objective method that enhances the accuracy of monocular 3D lane detection for both short- and long-distance scenarios while at the same time providing a fair amount of hardware acceleration. 3DLaneNAS utilizes a new multi-objective energy function to optimize the architecture of feature extraction and feature fusion modules simultaneously. Moreover, a transfer learning mechanism is used to improve the convergence of the search process. Experimental results reveal that 3DLaneNAS yields a minimum of 5.2 % higher accuracy and 1.33 * lower latency over competing methods on the synthetic-3D-lanes dataset.
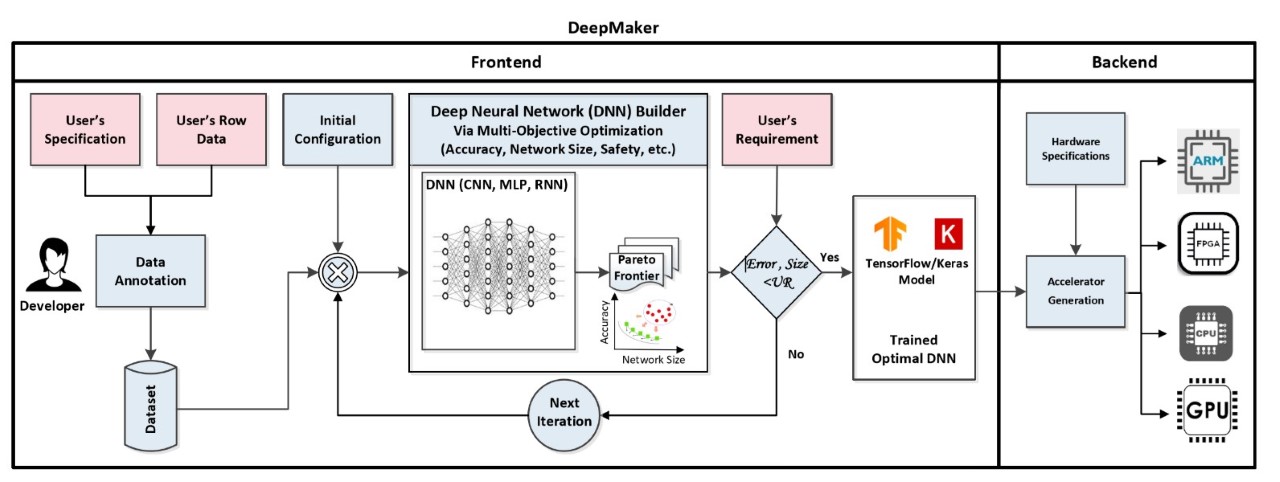
DeepMaker - Deep Learning Accelerator on Programmable Devices
In recent years, deep neural networks (DNNs) has shown excellent performance on many challenging machine learning tasks, such as image classification, speech recognition, and unsupervised learning tasks. The Complex DNNs applications require a great amount of computation, storage, and memory bandwidth to provide a desirable trade-off between accuracy and performance which makes them not suitable to be deployed on resource-limited embedded systems. DeepMaker aims to provide optimized DNN models including Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) that are customized for deployment on resource-limited embedded hardware platforms. To customize DNN for resource-limited embedded platforms, we have proposed this framework, with the aim of automatic design and optimization of deep neural architectures using multi-objective Neural Architecture Search (NAS). In the DeepMaker project [1][2][3], we have proposed novel architectures that are able to do inference in run-time on embedded hardware, while achieving significant speedup/ performance with negligible accuracy loss. Furthermore, to accelerate the inference of DNN on resource-limited embedded devices, we also consider using quantization techniques as one of the most popular and efficient techniques to reduce the massive amount of computations and as well the memory footprint and access in deep neural networks [4][5][6].
TAS: Ternarized Neural Architecture Search for Resource-Constrained Edge Devices
Deep Neural Networks (DNNs) have successfully been adapted to various computer vision tasks. In general, there is an increasing demand to deploy DNNs onto resource-constrained edge devices due to energy efficiency, privacy, and stable connectivity concerns. However, the enormous computational intensity of DNNs cannot be supported by resource-constrained edge devices leading to the failure of existing processing paradigms in affording modern application requirements. A Ternary Neural Network (TNN), where both weights and activation functions are quantized to ternary tensors, is a variation of network quantization techniques that comes with the benefits of network compression and operation acceleration. However, TNNs still suffer from a substantial accuracy drop issue, hampering them from being widely used in practice. Neural Architecture Search (NAS) is a method which can automatically design high-performance networks. The idea of our proposed framework, dubbed TAS, is to integrate the ternarization mechanism into NAS with the hope of reducing the accuracy gap of TNNs.

DeepHLS V1.0
DeepHLS is a fully automated toolchain for creating a C-level implementation that is synthesizable with HLS Tools. It includes various stages, including Keras to C, Validation, Quantization analysis, and Quantization application. Thanks to its various scalability features, it supports very large deep neural networks such as VGG.

DeepAxe
While the role of Deep Neural Networks (DNNs) in a wide range of safety-critical applications is expanding, emerging DNNs experience massive growth in terms of computation power.
It raises the necessity of improving the reliability of DNN accelerators yet reducing the computational burden on the hardware platforms, i.e., reducing the energy consumption and execution time as well as increasing the efficiency of DNN accelerators.
Therefore, the trade-off between hardware performance, i.e., area, power, and delay, and the reliability of the DNN accelerator implementation becomes critical and requires tools for analysis.
DeepAxe, an extention to DeepHLS, is a framework and tool for design space exploration of FPGA-based implementation of DNNs by considering the trilateral impact of applying functional approximation on accuracy, reliability, and hardware performance.

CoMA: Configurable Many-core Accelerator for Embedded Systems
We have developed the Configurable Many-core Accelerator (CoMA) for (FPGA-based) embedded systems. Its architecture comprises an array of processing and I/O-specialized cores interconnected by NoC. The I/O cores provide the connectivity with other system components through the industry-standard Advanced eXtensible Interface (AXI) bus. In a typical design flow, an application is partitioned and the most compute-demanding tasks are executed on the accelerator. With the proposed approach, the details of task synchronization and I/O access of the accelerator are hidden by an abstraction layer. Task partitioning is left to the designer, thus allowing more flexibility during application development than with automatized partitioning. The high level view of the system leverages the customization of the accelerator on an application basis. This way, CoMA promotes the development of many-core solutions for highly specialized applications.
CGRA: Configurable Many-core Accelerator for Embedded Systems
The increasing speed and performance requirements of multimedia and mobile applications, coupled with the demands for flexibility and low non-recurring engineering costs, have made reconfigurable hardware a very popular implementation platform. We have developed a Coarse Grained Reconfigurable Architectures (CGRA), provide operator level configurable functional blocks, word level data paths, and very area- efficient routing switches. Compared to the fine-grained architectures (like FPGAs), the CGRA not only requires lesser configuration memory and time but also achieves a significant reduction in area and energy consumed per computation, at the cost of a loss in flexibility compared to bit-level operations. Our CGRA has been developed based on the the Dynamically Reconfigurable Resource Array (DRRA) composed of three main components: (i) system controller, (ii) computation layer, and (iii) memory layer. For each hosted application in CGRA, a separate partition can be created in memory and computation layers. The partition is optimal in terms of energy, power, and reliability.
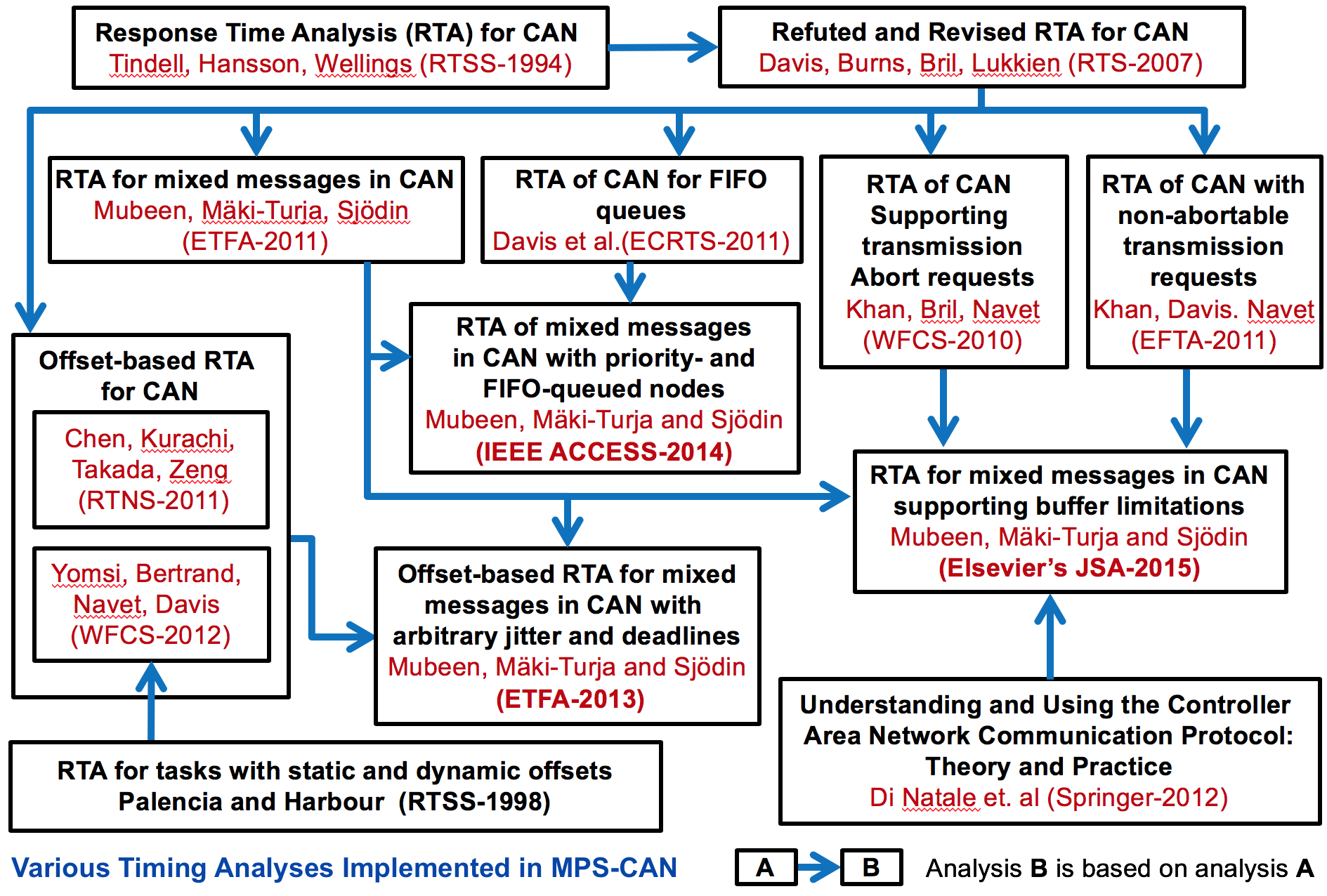
MPS-CAN Analyzer
MPS-CAN Analyzer (a freeware tool developed by us) is a response time analyzer for Mixed Periodic and Sporadic messages in Controller Area Network (CAN). It implements a number of response-time analyses for CAN addressing various queueing policies, buffer limitations in the CAN controllers, and various transmission modes implemented by higher-level protocols for CAN. It also integrates the response-time analysis for Ethernet AVB and CAN-to-Ethernet AVB Gateway.
Rubus-ICE
A commercial tool suite developed by Arcticus Systems and used in the vehicle industry to which we have contributed.
Rubus ICE (Integrated Component Model Development Environment which we have contributed to) provides an integrated environment for model-driven software development of applications ranging from small time-critical embedded systems to very large mixed time-critical and non-time critical embedded systems.
MECHAniSer
A freeware tool suite developed by Matthias Becker to support design and analysis of cause-effect chains in automotive systems.